基于 SpringBoot 的在线 Java IDE
- 功能
- 在线的 Java IDE,可以远程运行客户端发来的 Java 代码的 main 方法
- 将程序的标准输出内容、运行时异常信息反馈给客户端
- 对客户端发来的程序的执行时间进行限制 (线程池,future.get(limitTime))
- 涉及Java 基础的知识
- Java 程序编译过程: (运行时编译) 内存-内存
- 运行的过程:自定义类加载器实现类的加载 & 热替换
- Java 类加载机制
- Java 类文件结构: 根据 Java 类文件结构修改类的字节码,可将客户端程序对 System 的调用替换为对 System的替代类 HackSystem 的调用
- Java 反射:通过反射实现 main 方法的运行
- 一个简单的并发问题:如何将一个非线程安全的类变为一个线程安全的类 : 解决多用户同时发送执行代码请求时的并发问题: 通过 ThreadLoacl 实现线程封闭,为每个请求创建一个输出流存储标准输出及标准错误结果;
项目架构
在线执行 Java 代码的实现流程,架构如下图所示:

##正常情况下Java 程序编译和运行的过程
简要分析

1. 编译 :.java 源代码 javac 编译成 .class / jar包(其中都是.class)
- 加载:然后通过类的加载 classLoader, 双亲委派模型, 在JVM的方法区中得到类class对象
- 使用: JVM通过方法区中的class对象,获取该类的各种信息,或者运行该类的方法
- 程序入口的:指定类的main()
- 执行:通过JIT 编译,将class字节码 –> native code 交给OS执行
详细分析
编译
在运行前,我们首先需要将 .java 源文件编译为 .class 文件。Java 编译一个类时,如果这个类所依赖的类还没有被编译,编译器就会先编译这个被依赖的类,然后引用,否则直接引用,如果 Java 编译器在指定目录下找不到该类所其依赖的类的 .class 文件或者 .java 源文件的话,编译器话报“cant find symbol”的 Error。
运行
Java 类运行的过程可分为两个过程:
- 类的加载
- 应用程序运行后,系统就会启动一个 JVM 进程,JVM 进程从 classpath 路径中找到名为 Test.class 的二进制文件(假设客户端发来的类名为 Test),将 Test 的类信息加载到运行时数据区的方法区内,这个过程叫做 Test 类的加载。
- 上一步过程主要通过 ClassLoader 完成,类加载器会将类的字节码文件加载为 Class 对象,存放在 Java 虚拟机的方法区中,之后 JVM 就可以通过这个 Class 对象获取该类的各种信息,或者运行该类的方法。
- 关于类加载器的详细讲解可见:虚拟机类加载机制。
- 类的执行
- JVM 找到 Test 的主函数入口,开始执行 main 函数。
- 本项目主要通过反射来完成这一过程,有关反射的详细讲解可见:Java 反射。
本项目内用户传进来的Java 程序编译和运行的过程

编译
说明
- JDK 1.6 后新加的动态编译实现
compiler 1
2
3
43. 进行一些修改 实现从内存(String)-内存(bytes[])编译 (硬盘(.java)-硬盘(.class)
1. 后到的请求覆盖之前的.class
2. 保存在硬盘 不安全
4. ```Boolean result = compiler.getTask(null, manager, collector, options, null, Arrays.asList(javaFileObject)).call(); // 执行编译最关键的六个参数解析
1 | JavaCompiler.CompilationTask getTask(Writer out, |
out:编译器的一个额外的输出 Writer,为 null 的话就是 System.err;options:编译器的配置;javac - -target 1.8 -d /…….classes:需要被 annotation processing 处理的类的类名;nulldiagnosticListener:诊断信息收集器;service传入;如果编译出错,编译模块返回字节码null,将错误信息返回前端compilationUnits:要被编译的单元们,就是一堆 JavaFileObjectfileManager:文件管理器, 用以new JavaFileObject 存储编译好的byteCode
- compiler 编译过程源码流程

执行流程说明:
- 调用 JavaFileObject 的 getCharContent 方法,得到源码的字符序,返回类型 CharSequence接口(String,StringBuilder,StringBuffer实现)
- disk-disk: File – CharSequence
- mem- mem 实现一个自己的javaFileObject extends SimpleJavaFileObject
- 声明 private String source; 用以存储用户传入的代码,通过构造函数传入
- 重写 getCharContent() ,在其中返回 source
- 输入就搞定了,继续追源码,下面一个问题 就是 如何输出字节码,对于disk-disk 也就是如何将字节码写入磁盘
- 两个步骤:
- 1.JavaFileManager的 getJavaFileForOutput()方法获得JavaFileObject 对象 ,将编译得到字节码,封装进一个 JavaFileObject 对象;compiler调用完就找不到了
- 2.JavaFileObject 方法的openOutputStream() 来创建输出流对象,在compiler执行的过程中(具体啥时候不清楚) 会用这个输出流 保存到disk;
- 对于我们的目标–mem-mem
- JavaFileObject
- 重写自定义JavaFileObject 方法的openOutputStream() ,把该方法创建的输出流设为自定义JavaFileObject 的私有域,保存字节码
- 编译模块最终得到的其实是byte[],这个自定义的类中还有一个方法负责将输出流转为byte[]
- JavaFileManager
- 其 getJavaFileForOutput()搞出来的JavaFileObject ,compiler调用完就找不到了,所以说在自定义的编译模块中放一个 编译模块类的map里,key的话是classname,(不问的话不必说:value就是JavaFileObject 编译模块非并发,一个考虑就是避免不同请求,类名key相同把value覆盖)
- 另一个是说: getJavaFileForOutput()搞出来的JavaFileObject要是我们自己定义的JavaFileObject,只有这样才能操作其输出流
- 整体来说 就是实现自己的JavaFileManager,重写 getJavaFileForOutput()方法:1. new自定义JavaFileObject 2. 存入map 3. 返回
代码
我们实现的 SimpleJavaFileObject 的子类如下:
1 | public static class TmpJavaFileObject extends SimpleJavaFileObject { |
JavaFileManager fileManager
对于 JavaFileManager,我们需要重写以下 2 个方法:
1 | public static class TmpJavaFileManager extends ForwardingJavaFileManager<JavaFileManager> { |
实现编译器模块
最后,我们的编译器实现如下,通过调用 StringSourceCompiler.compile(String source) 就可以得到字符串源代码 source 的编译结果。
1 | //StringSourceCompiler 的执行是 非并发的 |
加载:
注意点:
- 绝不可以通过系统可以提供给我们的应用程序类加载器来加载用户传进来的类
- 因为这个类加载器是独一份的,如果通过这个类加载器加载了我们的字节码,当客户端对源码进行了修改,再次提交运行时,应用程序类加载器会认为这个类已经加载过了,不会再次加载它
- 这样除非重启服务器,否则我们永远都无法执行客户端提交来的新代码
至于说 为什么 应用程序类加载器会认为这个类已经加载过了,就要提到双亲委派模型
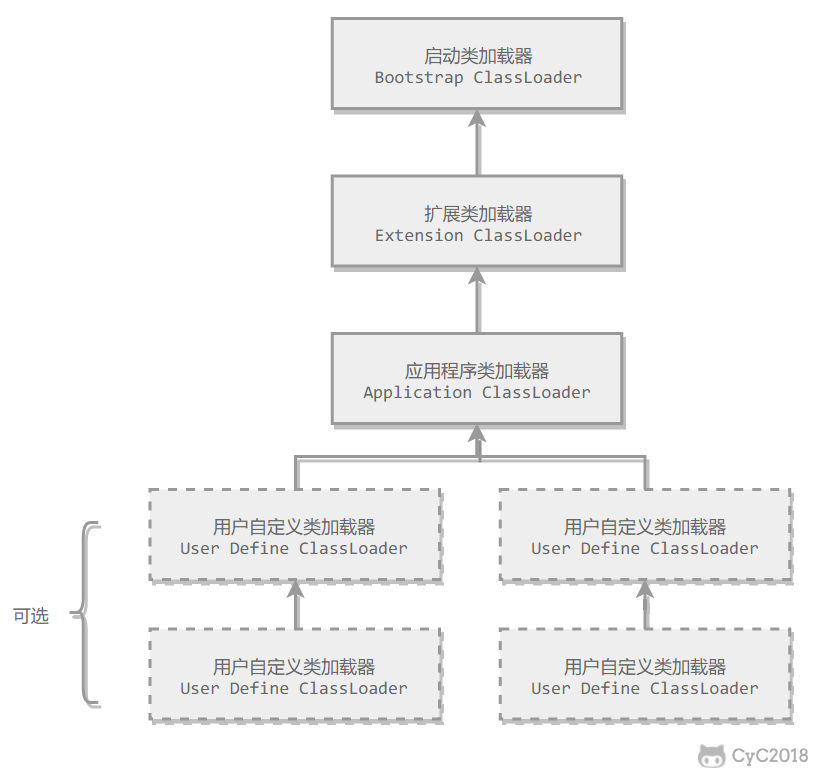
详细的双亲委派模型 不多说,但是在系统类加载器 systemClassLoader 源码里 loadClass()方法里的双亲委派模型的逻辑是这样的
1 | public abstract class ClassLoader { |
之前的问题:为什么 应用程序类加载器会认为这个类已经加载过了
答案:双亲委派模型中的一步,类加载器会通过类的全限定名查找该类加载器已经加载过的类 查找方法findLoadedClass(name 类全限定名)
我们想要解决的问题就是:1. 有两个类全限定名一样的字节码 (全限定名) 2. 需要他们是不同的类class对象
类加载器会通过类的全限定名查找该类加载器已经加载过的类 —- 可以推出—–>两个类相同的条件
- 类的全限定名相同
- 被同一个类加载器加载
要解决我们的问题就可以 破坏第二个条件 :加载一个用户请求的类,就用一个新的类加载器,并且不遵守双亲委派模型
通过protected final Class<?> defineClass(String name, byte[] b, int off, int len) 来完成,
所以我们只要新写一个 loadByte 方法把 defineClass 方法开放出来,我们自己要使用 HotswapClassLoader 加载类时就显式调用 loadByte 方法
虚拟机使用 HotswapClassLoader 时会去调用 loadClass 方法 (虚拟机会使用自定义的类加载器吗? 会的 类加载的传递性原则)
类加载的传递性原则 程序在运行过程中,遇到了一个未知的类,它会选择哪个 ClassLoader 来加载它呢?
虚拟机的策略是使用调用者 Class 对象的 ClassLoader 来加载当前未知的类。何为调用者 Class 对象?就是在遇到这个未知的类时,虚拟机肯定正在运行一个方法调用(静态方法或者实例方法),这个方法挂在哪个类上面,那这个类就是调用者 Class 对象。前面我们提到每个 Class 对象里面都有一个 classLoader 属性记录了当前的类是由谁来加载的。
也就是在用户传入的类中,如果有一个未加载过的 非用户自定义的类,VM会使用我们自定义的类加载器的loadClass()方法加载,遵守双亲委派
HotswapClassLoader 具体实现如下:
1 | public class HotSwapClassLoader extends ClassLoader { |
然后使用我们新写的类加载器,我们就可以通过以下两行代码无数次的加载客户端要运行的类了!
1 | HotSwapClassLoader classLoader = new HotSwapClassLoader(); |
使用:
将类加载进虚拟机之后,我们就可以通过反射机制来运行运行用户类的 main 方法了。
1 | Method mainMethod = clazz.getMethod("main", new Class[] { String[].class }); |
用户的结果输出:
经过
1. 编译模块的运行时编译,
2. 在执行模块,对每个用户请求传入的类都是用一个自定义的类加载器加载,
3. 然后使用反射运行main方法
可以完成,用户请求代码的运行,但是有一点问题:用户的输出如何获得?
用户输出:一般通过 System.out, 那么如何获取其中的内容
方案一:System.out 是一个PrintStream 显然可以通过 System.out.toString()获取其中内容 或者System.setOut()重定向输出流,然后获取其中内容
方案一问题:1. 每个用户的请求的执行操作都是在一个线程里跑的,并发的,那么所有用户的请求的输出流都会混在一个System.out里面,显然不可取
想要的目标:每个线程的输出流都独立 –> 很自然达到这个需求 就是ThreadLocal –> 为了在输出流中使用ThreadLocal需要继承PrintStream 写一个线程封闭的输出流
实现线程封闭的PrintStream类
主要思路:
继承PrintStream,实现线程封闭的子类(PrintStream类不是final的可以继承)
找到PrintStream中存储 流 的成员,改为ThreadLocal的
PrintStream有一个继承自其父类的成员
OutputStream out,输出基本依靠该成员PrintStream不抛出异常,而是使用
Boolean trouble记录是否产生异常- 因此在自定义的PrintStream类中 将这两个变量实现为ThreadLocal的
查看System类中是否有使用到PrintStream 类型out的方法 (没有,也就是一般是System.out使用)
System类中没有使用到PrintStream 类型out的方法,也就是一般是System.out使用
但是PrintStream的无参构造函数肯定会用到 (初始化System 的out成员)
1
2
3> private ThreadLocal<ByteArrayOutputStream> out;
> private ThreadLocal<Boolean> trouble;
>
查找PrintStream类中的public 方法,改为线程封闭的
改造方法:将相关方法(out 和 trouble相关的方法) 由线程同步的Synchronized(this)的 改为 从ThreadLocal类型的out中 先get()再操作
改写的方法:ensureOpen ,close ,write |||||||| setError,checkError,clearError
ensureOpen 方法
PrintStream 中的实现:
1
2
3> private void ensureOpen() throws IOException {
> if (out == null) throw new IOException("Stream closed");}
>重写为:
1
2
3
4
5> private void ensureOpen() throws IOException {
> if (out.get() == null) { // 不是判断out是否为空,而是判断out.get()是否为空
> out.set(new ByteArrayOutputStream()); // 如果为空不再抛出异常,而是新建一个流给调用这个方法的线程
> }}
>close 方法
PrintStream 中的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14> private boolean closing = false; /* To avoid recursive closing */
> public void close() {
> synchronized (this) {
> if (!closing) {
> closing = true;
> try {
> textOut.close();
> out.close();}
> catch (IOException x) {
> trouble = true; }
> textOut = null;
> charOut = null;
> out = null; } } }
>重写为:
1
2
3
4
5
6
7
8> public void close() {
> try {// 关闭当前线程的OutputStream
> out.get().close(); }
> catch (IOException x) {
> trouble.set(true);}
> out.remove(); // 将当前线程的OutputStream移除
> }
>write 方法
PrintStream 中的实现:
1
2
3
4
5
6
7
8
9
10
11
12> public void write(byte buf[], int off, int len) {
> try {
> synchronized (this) {
> ensureOpen();
> out.write(buf, off, len);
> if (autoFlush)
> out.flush();} }
> catch (InterruptedIOException x) {
> Thread.currentThread().interrupt(); }
> catch (IOException x) {
> trouble = true; }}
>重写为:
1
2
3
4
5
6
7
8
9
10> public void write(byte buf[], int off, int len) {
> try {
> ensureOpen();
> out.get().write(buf, off, len); // out.get()才是当前线程的OutputStream
> }
> catch (InterruptedIOException x) {
> Thread.currentThread().interrupt(); }
> catch (IOException x) {
> trouble.set(true); } }
>
修改System类
承接上段*有了自定义的PrintStream输出流就可以在执行模块执行前,使用System.setOut()将输出流重定向至线程独立的输出流*
但没有这么做
原因在于System类本身也有很多不安全的地方 比如 System.exit(0),用户调用该方法直接关掉整个服务—>需要修改System类,限制用户使用不安全的方法
将 System 替换为 HackSystem 的思路
那么如何将客户端程序中对 System 的调用替换为对 HackSystem 的调用呢?当然不能直接修改客户端发来的程序的源代码字符串了,这既不优雅,操作也十分的繁琐。我们采用了一种“高级”的方法,即直接在字节码中,把要执行的类对 System 的符号引用替换为我们准备的 HackSystem 的符号引用,因此我们需要一个字节码修改器,这个字节码修改器完成如下流程:
- 遍历字节码常量池中的所有符号引用,找到 “java/lang/System”;
- 将 “java/lang/System” 替换为 “…/HackSystem”。
要想完成以上 2 步操作,首先我们要了解类文件的结构,这样我们才能找到类对 System 的符号引用的位置,并且知道替换的方法;其次,我们还需要一个字节数组修改工具 ByteUtils 帮助我们修改存储字节码的字节数组。
类文件结构
这里,为了不影响阅读的流畅性,我们只简单介绍一下我们会用到的有关类文件结构的内容。
Class 文件是一组以 8 位字节为基础单位的二进制流,各个数据项目严格按照顺序紧凑地排列在 Class 文件中,中间没有任何分隔符。Java 虚拟机规范规定 Class 文件采用一种类似 C 语言结构体的伪结构来存储数据,这种伪结构中只有两种数据类型:无符号数和表,我们之后也主要对这两种类型的数据类型进行解析。
- 无符号数: 无符号数属于基本数据类型,以 u1、u2、u4、u8 分别代表 1 个字节、2 个字节、4 个字节和 8 个字节的无符号数,可以用它来描述数字、索引引用、数量值或 utf-8 编码的字符串值。
- 表: 表是由多个无符号数或其他表为数据项构成的复合数据类型,名称上都以
_info结尾。
Class 文件的头 8 个字节
Class 文件的头 8 个字节是魔数和版本号,其中头 4 个字节是魔数,也就是 0xCAFEBABE,它可以用来确定这个文件是否为一个能被虚拟机接受的 Class 文件(这通过扩展名来识别文件类型要安全,毕竟扩展名是可以随便修改的)。
后 4 个字节则是当前 Class 文件的版本号,其中第 5、6 个字节是次版本号,第 7、8 个字节是主版本号。
常量池
从第 9 个字节开始,就是常量池的入口,常量池是 Class 文件中:
- 与其他项目关联最多的的数据类型;
- 占用 Class 文件空间最大的数据项目;
- Class 文件中第一个出现的表类型数据项目。
常量池的开始的两个字节,也就是第 9、10 个字节,放置一个 u2 类型的数据,标识常量池中常量的数量 cpc (constant_pool_count),这个计数值有一个十分特殊的地方,就是它是从 1 开始而不是从 0 开始的,也就是说如果 cpc = 22,那么代表常量池中有 21 项常量,索引值为 1 ~ 21,第 0 项常量被空出来,为了满足后面某些指向常量池的索引值的数据在特定情况下需要表达“不引用任何一个常量池项目”时,将让这个索引值指向 0 即可。
常量池中记录的是代码出现过的所有 token(类名,成员变量名等,也是我们接下来要修改的地方)以及符号引用(方法引用,成员变量引用等),主要包括以下两大类常量:
- 字面量:接近于 Java 语言层面的常量概念,包括
- 文本字符串
- 声明为 final 的常量值
- 符号引用:以一组符号来描述所引用的目标,包括
- 类和接口的全限定名
- 字段的名称和描述符
- 方法的名称和描述符
常量池中的每一项常量都通过一个表来存储。目前一共有 14 种常量,不过麻烦的地方就在于,这 14 种常量类型每一种都有自己的结构,我们在这里只详细介绍两种:CONSTANT_Class_info 和 CONSTANT_Utf8_info。
CONSTANT_Class_info 的存储结构为:
1 | ... [ tag=7 ] [ name_index ] ... |
其中,tag 是标志位,用来区分常量类型的,tag = 7 就表示接下来的这个表是一个 CONSTANT_Class_info,name_index 是一个索引值,指向常量池中的一个 CONSTANT_Utf8_info 类型的常量所在的索引值,CONSTANT_Utf8_info 类型常量一般被用来描述类的全限定名、方法名和字段名。它的存储结构如下:
1 | ... [ tag=1 ] [ 当前常量的长度 len ] [ 常量的符号引用的字符串值 ] ... |
在本项目中,我们需要修改的就是值为 java/lang/System 的 CONSTANT_Utf8_info 的常量,因为在类加载的过程中,虚拟机会将常量池中的“符号引用”替换为“直接引用”,而 java/lang/System 就是用来寻找其方法的直接引用的关键所在,我们只要将 java/lang/System 修改为我们的类的全限定名,就可以在运行时将通过 System.xxx 运行的方法偷偷的替换为我们的方法。
因为我们需要修改的内容在常量池中,所以我们就介绍到常量池为止,不再介绍 Class 文件中后面的部分了,接下来我们将要介绍修改字节码常量池时会用到的一个处理字节数组的小工具:ByteUtils。
ByteUtils 工具
这个小工具主要有以下几个功能:
- byte to int
- int to byte
- byte to String
- String to byte
- 替换字节数组中的部分字节
具体实现详见:ByteUtils.java
实现字节码修改器
介绍完会用到的基础知识,接下来就是本篇的重头戏:实现字节码修改器。通过之前的说明,我们可以通过以下流程完成我们的字节码修改器:
- 取出常量池中的常量的个数 cpc;
- 遍历常量池中 cpc 个常量,检查 tag = 1 的 CONSTANT_Utf8_info 常量;
- 找到存储的常量值为 java/lang/System 的常量,把它替换为 org/olexec/execute/HackSystem;
- 因为只可能有一个值为 java/lang/System 的 CONSTANT_Utf8_info 常量,所以找到之后可以立即返回修改后的字节码。
具体实现详见:ClassModifier.java
并发相关
Async注解
https://blog.csdn.net/wudiyong22/article/details/80747084
SimpleAsyncTaskExecutor:不是真的线程池,这个类不重用线程,每次调用都会创建一个新的线程。
ThreadPoolTaskExecutor :
最常使用,推荐。 其实质是对java.util.concurrent.ThreadPoolExecutor的包装
配置线程池参数,注册为bean
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
241、corePoolSize:核心线程数 CPU+1
* 核心线程会一直存活,及时没有任务需要执行
* 当线程数小于核心线程数时,即使有线程空闲,线程池也会优先创建新线程处理
* 设置allowCoreThreadTimeout=true(默认false)时,核心线程会超时关闭
2、queueCapacity:任务队列容量(阻塞队列)ArrayBlockingQueue(0)
* 当核心线程数达到最大时,新任务会放在队列中排队等待执行
3、maxPoolSize:最大线程数 CPU+1
* 当线程数>=corePoolSize,且任务队列已满时。线程池会创建新线程来处理任务
* 当线程数=maxPoolSize,且任务队列已满时,线程池会拒绝处理任务而抛出异常
4、keepAliveTime:线程空闲时间
* 当线程空闲时间达到keepAliveTime时,线程会退出,直到线程数量=corePoolSize
* 如果allowCoreThreadTimeout=true,则会直到线程数量=0
5、rejectedExecutionHandler:任务拒绝处理器
* 两种情况会拒绝处理任务:
- 当线程数已经达到maxPoolSize,切队列已满,会拒绝新任务
- 当线程池被调用shutdown()后,会等待线程池里的任务执行完毕,再shutdown。如果在调用shutdown()和线程池真正shutdown之间提交任务,会拒绝新任务
* 线程池会调用rejectedExecutionHandler来处理这个任务。如果没有设置默认是AbortPolicy,会抛出异常
* ThreadPoolExecutor类有几个内部实现类来处理这类情况:
- AbortPolicy 丢弃任务,抛运行时异常
- CallerRunsPolicy 执行任务
- DiscardPolicy 忽视,什么都不会发生
- DiscardOldestPolicy 从队列中踢出最先进入队列(最后一个执行)的任务
* 实现RejectedExecutionHandler接口,可自定义处理器
6、allowCoreThreadTimeout:允许核心线程超时Future.get() 实现超时限制
- 捕获异常 RejectedExecutionException/TimeoutException
限制客户端程序的运行时间
我们并不知道客户端发来的程序的实际运行时间,出于安全的角度考虑,我们需要对其运行时间进行限制。
在 ExecuteStringSourceService 中,我们通过使用 Callable + Future 的方式来限制程序的执行时间,并且对运行过程中可能出现的错误进行 catch,返回给客户端。
1 | ExecutorService pool = Executors.newSingleThreadExecutor(); |

